Introducing AGI-01 Swift, Powered by the World Engine
Meet AGI-01 Swift, our fast default for everyday work, built on the World Engine: an ultra-connected internal harness that multiplies the capability of the models it runs on, grounding, routing, and verifying every answer.
A Model Is Not the Whole Story Anymore
For most of the last few years, getting a better answer meant reaching for a bigger model. More parameters, more pretraining, more cost, and eventually diminishing returns. A single model, however large, still answers from a fixed snapshot of what it absorbed during training. It cannot consult today's facts, it cannot guarantee an exact calculation, and when it reaches the edge of what it actually knows, it tends to produce something fluent rather than something true.
That last failure is not an accident of scale, and it is worth being precise about why. Today we are introducing AGI-01 Swift, our fast default for everyday work, and the system that changes its behavior at the root: the World Engine.
Why Language Models Fail in Predictable Ways
To explain what the World Engine does, it helps to be honest about how a language model actually works under the surface. A model of this kind is trained to estimate the probability of the next token given everything before it. Its entire objective is to make plausible text more likely. Truth is not a term in that objective. The model has no internal variable that separates "I have verified this" from "this is a statistically natural continuation."
Several well-known weaknesses fall directly out of that single fact.
Hallucination
When a prompt lands in a region the model saw densely during training, its most probable continuation usually happens to be correct. When a prompt lands in a sparse region, such as a long-tail fact, a recent event, a precise figure, or a niche citation, the model still emits a confident, fluent continuation, because abstaining is not the behavior its training rewards. The output is not a lie in any intentional sense. It is the maximum-likelihood guess of a system that was never given a mechanism to know it is guessing. Confidence, in a language model, is a property of the token distribution, not of evidence. This is why models can be wrong and fluent at the same time, which is precisely the most dangerous combination for a user to evaluate.
Laziness and shortcutting
Preference tuning, the stage that makes a raw model feel helpful, optimizes for answers that humans rate well. Reward models reward surface features of a good answer: completeness, confidence, a tidy structure. That pressure quietly incentivizes effort-minimizing shortcuts. A model learns that a generic, confident, well-formatted response often scores nearly as well as a careful one, so on hard prompts it will sometimes hedge, truncate, or generalize rather than do the work. What looks like laziness is a rational response to how the reward was shaped.
Complex, compositional problems
Real-world problems are rarely a single step. They are chains: gather a fact, compute on it, compare the result, decide. Autoregressive generation conditions every step on the tokens already produced, so an early mistake does not stay contained. It becomes a premise the model now treats as given. Error compounds across steps roughly multiplicatively, which is why a model can be individually competent at each sub-skill yet unreliable on the composed task. The bottleneck is rarely any one step. It is the accumulation, and the absence of any external check that could catch the drift before it propagates.
Add the well-documented tokenization traps, where character-level questions fail because the model reasons over tokens rather than letters, and a clear picture emerges. These are not signs of a weak model. They are structural consequences of how the technology works. Scaling the model alone does not remove them. It only moves the threshold at which they appear.
Introducing AGI-01 Swift
AGI-01 Swift is designed to be the model you reach for by default. It is fast, responsive, and built for the bulk of real work: writing, search, coding, reasoning, image understanding, and lightweight agent workflows. It moves quickly and stays useful without overthinking simple tasks.
But Swift is more than a model behind an endpoint. When you call it, you are talking to a coherent assistant backed by something larger and more deliberate.
The model is what you talk to. The World Engine is what makes the answer trustworthy.
What Is the World Engine?
The World Engine is the system AGI-01 Swift runs on. What you talk to is one product with one consistent voice. What stands behind it is neither a lone model nor a bundle of models stitched together: it is a tightly connected internal harness that lets Swift reach for the right capability at the right moment, exact computation, live information, visual analysis, deep domain skill, and weave the results back into one clean answer.
The design principle is to relocate the burden of being correct away from probabilistic recall. Answering from memory alone means a system has to remember a fact, simulate a calculation, and hope it composed the steps correctly. The World Engine instead lets Swift retrieve the fact, compute the calculation, and verify the composition. The difference is not cosmetic. It changes which parts of the answer depend on a guess and which parts depend on a check.
On the tasks it was built for, the World Engine multiplies the effective capability of the models it runs on, by an order of magnitude or more on targeted workloads. AGI-01 Swift is not a single set of weights we trained from scratch; it is what today's strongest open source models become once the World Engine grounds, routes, and verifies around them. The gain is not a model that suddenly knows more, but one that no longer has to guess where it could verify, compute, or look something up instead.
How the World Engine Addresses Each Failure Mode
Each of the weaknesses above has a specific structural answer in the harness.
Against hallucination: grounding instead of recall
When an answer depends on a current fact, the World Engine grounds it in live sources rather than memory. When it depends on a number, the model uses exact computation rather than estimation. When it depends on what is actually in a file or codebase, it inspects the real content rather than assuming. Each of these removes a situation in which the model would otherwise be forced to produce a confident guess. You cannot hallucinate a value you actually computed, or a source you actually read.
Against laziness: judgment separated from execution
The model is asked to do the one thing it is genuinely good at, which is judgment: understanding intent, deciding what the answer truly depends on, and assembling a coherent response. Precise execution is routed to where it is handled best. Because the demanding parts of the task are no longer competing for the model's effort against the temptation to shortcut, the easy path and the correct path stop diverging.
Against compounding error: verification between steps
Independent steps run in parallel for speed. Dependent steps run in sequence, so a later step always sees the verified result of an earlier one. Results that come back are accepted, checked, or sent back for a narrow targeted revision, never loosely rewritten. Because the harness keeps verified intermediate results authoritative and does not let the model casually overwrite them, the chain has far less room to drift. The conclusion follows the work rather than being rationalized after it.
Against the traps: mechanical discipline
On the questions that reliably fool models, such as counting letters in a word, comparing decimals like 9.9 and 9.11, or subtly altered versions of classic puzzles, Swift is built to slow down and work mechanically where intuition fails, and to solve the problem exactly as stated rather than pattern-matching to a famous version of it.
And when it still cannot be sure
When something cannot be verified, Swift is built to say what is known, what is inferred, and what would need checking, rather than papering over the gap. Calibrated abstention is a feature, not a failure. A narrow accurate answer is worth more than a broad confident one that happens to be wrong.
A single model guesses when it is unsure. A connected system checks, and admits what it cannot.
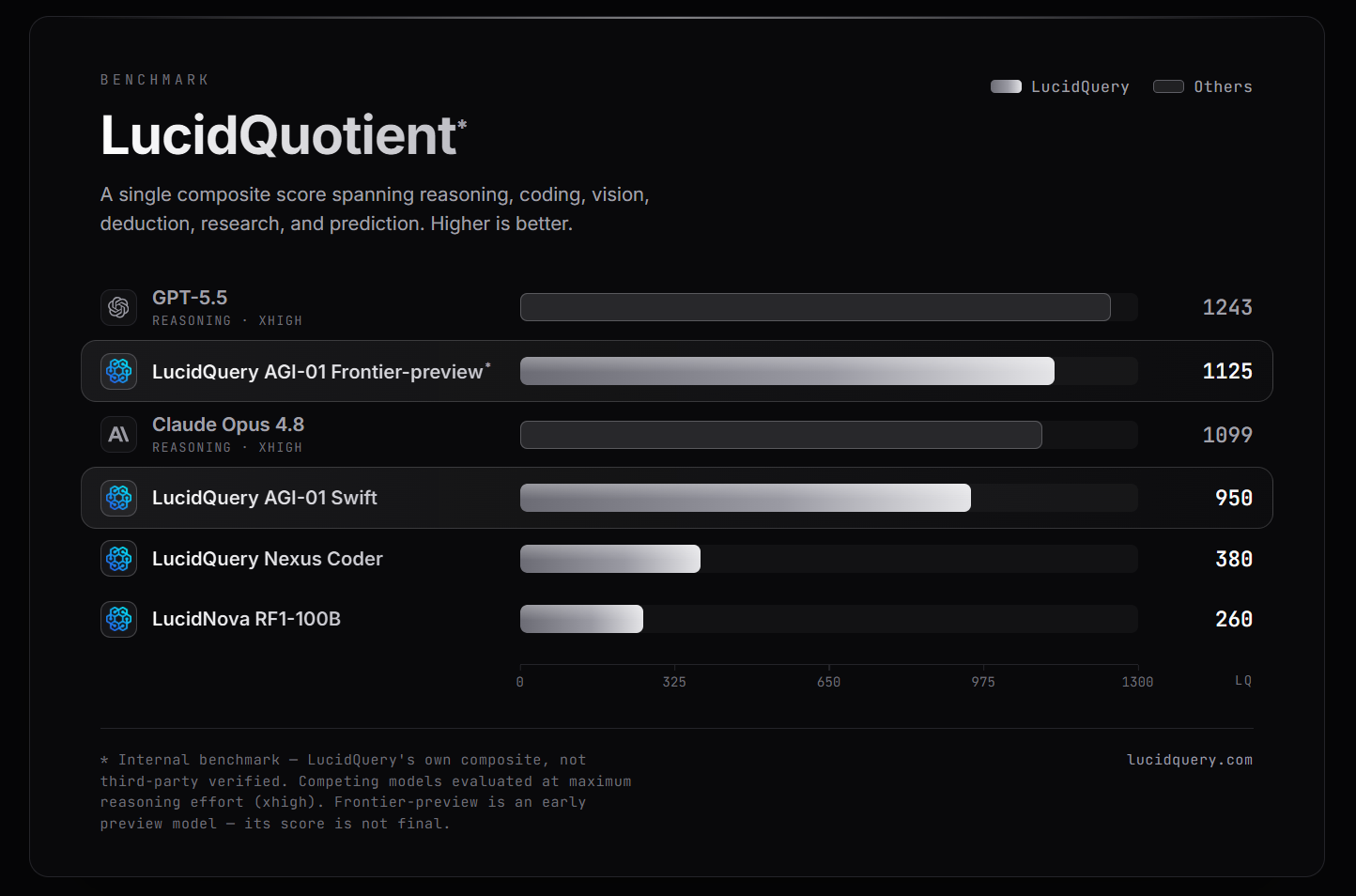
Measuring This: The LucidQuotient
Standard public benchmarks are useful but easy to overfit, and many have partially leaked into training corpora across the industry. To track real capability over time we maintain our own evaluation, the LucidQuotient, reported as a single LQ score where higher is better.
We keep the exact composition and weighting confidential, for the obvious reason that a benchmark you can see the inside of is a benchmark you can train toward. What we will say is what it is designed to stress. The LucidQuotient is built to measure end-to-end task success rather than single-shot recall, across a deliberately broad surface: multi-step reasoning, mathematics, graduate-level science, coding and code review, faithful instruction following, grounded and source-backed factual work, long-horizon tasks that span several dependent steps, and explicit resistance to the failure modes described above, including hallucination under sparse-knowledge prompts and the reliability traps. It is held out from training, refreshed to resist contamination, and weighted toward whether the whole task came out right, not whether an isolated answer looked plausible.
AGI-01 Swift scores 950 LQ. The point of the metric is not the number in isolation but what it rewards: a system is credited for being right for verifiable reasons, and penalized for confident error in exactly the regions where ungrounded models tend to fabricate.
Public Benchmarks
The same behavior shows up on familiar public benchmarks. All figures below are zero-shot, pass@1, at temperature 0.
| Benchmark | What it measures | AGI-01 Swift |
|---|---|---|
| HumanEval | Code · pass@1 | 94.7% |
| GPQA Diamond | Graduate-level science · pass@1 | 84.3% |
| MATH-500 | Mathematics · pass@1 | 98.2% |
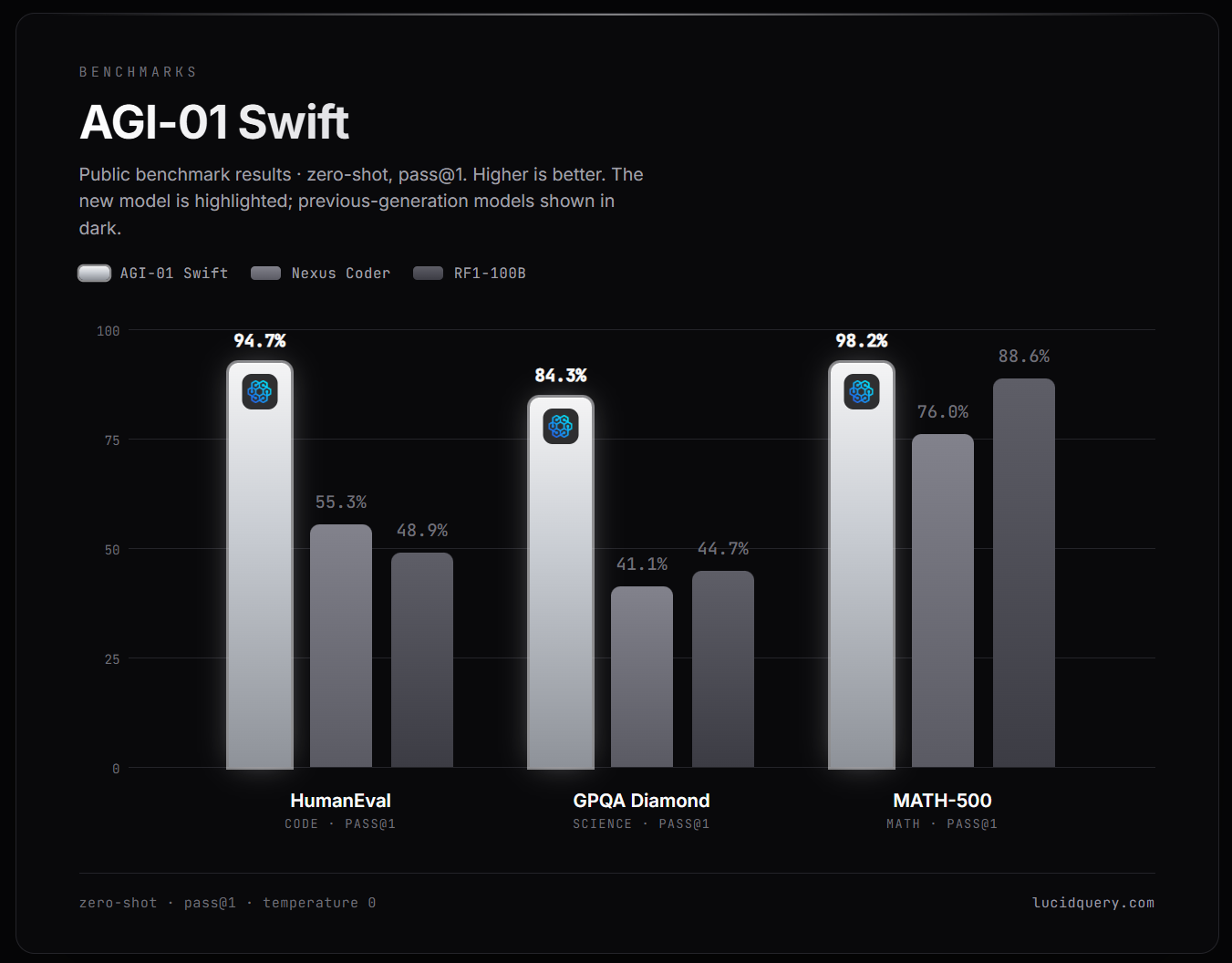
The mathematics result is a clean illustration of the principle. A fast model on its own makes occasional arithmetic and algebra slips, exactly the silent errors that compound in longer derivations. With exact computation available and verified inside the loop, those slips largely disappear.
What Swift Can Do
- Live web grounding: current, time-sensitive answers backed by real sources when it counts.
- Coding: generation, review, and refactoring, with correctness checks built into the flow.
- Exact math: arithmetic, algebra, calculus, and comparisons resolved by computation rather than estimation.
- Image and document understanding: reasoning over what is actually present in an image or file.
- Photo geolocation: pinpoint where a photo was taken from a single image, with ranked, confidence-aware results, powered by our StrikeLoc geolocation technology built directly into Swift.
- Agent-ready: full tool-call compatibility, so Swift slots cleanly into agent frameworks.
Built for Developers and Agents
AGI-01 Swift is available through our OpenAI-compatible API. If you already use the OpenAI SDK, you change one line, the base URL, and keep everything else. Streaming is on by default, so you can render tokens as they arrive.
from openai import OpenAI
client = OpenAI(
api_key="your_lucidquery_api_key",
base_url="https://api.lucidquery.com/v1",
)
response = client.chat.completions.create(
model="lucidquery-agi-01-swift",
messages=[
{"role": "user", "content": "What changed in the EU AI Act this year, and cite your sources."}
],
stream=True,
)
for chunk in response:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="")
Swift also preserves the tool contracts of external agent clients. When a caller provides its own tools, Swift uses that schema exactly, so it fits inside coding agents and automation workflows without breaking their protocols.
Pricing and Availability
AGI-01 Swift is available now, with the same transparent, pay-as-you-go pricing as the rest of the platform. No seats, no subscription, top up in euros.
- Input: €2.50 per 1M tokens
- Output: €15.00 per 1M tokens
- LucidQuotient: 950 LQ
- Model ID:
lucidquery-agi-01-swift
What Comes Next
Swift is the first member of the AGI-01 family to run on the World Engine, tuned for speed, the model you want for the everyday flow of real work. A deeper and more deliberate sibling, AGI-01 Frontier, is on the way for the problems that need more judgment. Both share the same connected foundation. They differ in how far they push it.
The shift underneath all of this is a change in the question we ask. It is no longer only "how large is the model." It is "how well is the model connected to the things that make an answer true."